Ultraschall 21 – Ducking von Sprache und Sounds in einem Podcast
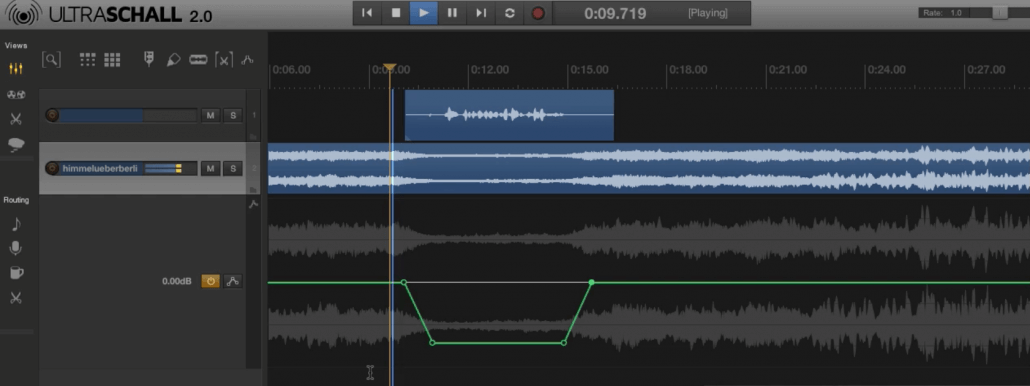
Ich zeige in dieser Folge, wie man auf verschiedenen Wegen die Verständlichkeit der eigenen Sprache in einem Podcast gegenüber Hintergrundsounds wie Jingles oder Musik verbessern kann. Das Grundprinzip ist einfach: Während man spricht, soll der Soundhintergrund leiser werden, danach wieder zur ursprünglichen Lautstärke zurückfinden.
Es gibt hier viele Wege: ich zeige den “robusten” Ansatz über einen Crossfade, Die Spurautomatipn über den Volume-Envelope, die manuelle Methode über unser Soundboard sowie die Profi-Variante über den Sidechannel-Kompressor, die dann auch in Echtzeit und automagisch während der Sendung funktioniert.
Für die Sidechannel-Kompression liefern wir seit Ultraschall 1.3 auch ein Projekt-Template mit, so dass sich dieses Setup in wenigen Sekunden nachbauen lässt.

Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!