tl;dr: Presonus hat den Software-Support der VSL-Soundinterfacereihe für OSX El Capitan eingestellt. Kein Beinbruch: mit Ultraschall/Reaper lassen sich bessere Ergebnisse erzielen.
Ausgangslage: immer Ärger mit Presonus
Über die schwierige Hassliebe von PodcasterInnen zu den VSL-Audiointerface-Produkten der Firma Presonus habe ich mich schon einmal länger ausgelassen. Zum einen bieten sie guten Klang, viele Eingänge und Echtzeit-Effekte zu ca. 50% des Preises, den andere Firmen für vergleichbare Features aufrufen. Zum anderen hatte man aber nie den Eindruck, dass die Treiber und Mixeroberflächen wirklich 100% robust waren. Jedes Apple-Update brachte Probleme mit sich. Die Informations- und Supportkultur von Presonus ist und bleibt eine Katastrophe.
Nun zu OSX El Capitan der Paukenschlag: jegliche Weiterentwicklung der VSL-Linie wird eingestellt. Der Gerechtigkeit halber für die Windows-Welt gleich mit. Äh – what? Nur weil Apple sonderbare (wenn wohl auch sinnvolle) Updates im Core-Audio-Bereich herausgibt, müssen die ca. 9/10tel Windows-KäuferInnen gleich mit leiden?
So tickt Presonus.
Wenn man die VSL-Politik wie ich seit Jahren verfolgt, ergibt sich hier ein klares Bild: Sie haben eigentlich von Tag 1 an die technischen Probleme dieser Modellreihe (Aussetzer, Knacksen) nie wirklich in den Griff bekommen und sehen das Update jetzt als willkommene Gelegenheit für einen Exit.
Etwas lapidar heißt es in ihrer Ankündigung (paraphrasiert): „Nun, Eure Interfaces funktionieren ja weiter als Class-Audio Geräte, ihr müsst nur unsere Treiber- und Mixersoftware komplett entfernen.“
Hier entsteht zunächst ein mehr als schaler Beigeschmack: Die VSL-Reihe war deshalb besonders, weil sie in ihrer Mixer-Software nicht nur ein brauchbares Routing zwischen den 8 Eingängen und 8 Ausgängen (!) ermöglichte, sondern vor allem auch für Podcasting hochinteressante Echtzeiteffekte mitbrachte: EQ, Kompressor, Limiter, Noisegate. Diese entfallen nun komplett ohne die Mixer-Software; übrig bleibt ein relativ schlichtes Stück Audio-Hardware, das lediglich Ein- und Ausgänge im OS bereitstellt. Da kann das mobile Zoom H6 mehr (von der Anzahl der Eingänge abgesehen).
Der Grund für all diese Probleme liegt in der sehr speziellen Treiberarchitektur der VSL-Geräte. Der niedrige Preis konnte nur realisiert werden, da in den Geräten schlicht nichts IST als simple Audio-Hardware – und eben keine teuren DSP-Effektbausteine wie bei der teuren Konkurrenz. Das Audio der VSL-Geräte wurde IMMER durch den USB-Stack des Rechners geroutet, softwareseitig durch die Mixer-Software mit Effekten angereichert und dann in die Hardware zurückgeschickt. Das erklärt auch, warum in den VSL-Geräten nie etwas zu hören ist, wenn sie nicht gleichzeitig an einem Rechner hängen – es gibt schlicht kein direktes, in Hardware gegossenes Monitoring im Gerät selbst.
Um nun diesen aufwändigen Weg durch den Rechner ohne allzu große Latenz gehen zu können, wurden etliche Tricks angewandt und Spezifikationen ausgereizt. Apple hat wiederum im Audio- und USB-Bereich – vor allem beim Wechsel von USB 2 nach 3 – sehr viel und wohl nicht immer glücklich an den Spezifikationen gedreht. Presonus – bzw. deren Programmier-Auftragsschmiede – kam da nur extrem schleppend hinterher (etlichen anderen Audio-Buden erging es jedoch ähnlich).
Die Situation ist also offiziell die: keine Effekte mehr, vermutlich kein Monitoring. Für nicht wenige PodcasterInnen eine mittlere Katastrophe.
@gglnx und @rstockm gehen in Klausur
@gglnx und ich wollten das so nicht hinnehmen. Mit viel Liebe hatten wir uns fesche Audio-Racks gebaut, bestehend aus 1818VSL und 8-Kanal Kopfhörerverstärker. Zumindest wollten wir sicher gehen, dass es wirklich keinen Ausweg gibt außer das Update auf El Capitan auszusetzen.

Praktisch im Rack mit einem 8-fach Kopfhörerverstärker
Unser grundsätzlicher Ansatz: Solange das Interface sauber gebaut ist, könnte es möglich sein zumindest die Monitoring-Funktionen über das Betriebssystem zu realisieren – oder noch besser über die DAW Aufnahmesoftware (Ultraschall/Reaper).
Im Ergebnis wäre so die Presonus-Software komplett überflüssig, man könnte dieselben Features direkt in Reaper/Ultraschall abbilden. Die Grundlegenden Mechanismen des Audio-Routings und Monitorings habe ich hier schon einmal erläutert.
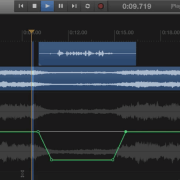
Entscheidend für die Alltagstauglichkeit einer solchen Lösung ist dabei die Latenz, also die Verzögerung, mit der das Audiosignal die Wegstrecke vom eigenen Mund über das Mikrofon, A-D Wandler, USB-Stack, DAW-Software, USB-Stack, D-A Wandler und zurück zum Kopfhörer zurücklegt. Gemessen wird die Latenz in Millisekunden (ms) – je kleiner, desto weniger Latenz und desto besser.
Wie misst man diese Latenz von Mikro zu Kopfhörer? Dazu habe ich eine eigene Ultraschall-Folge aufgenommen: Das verwendete Tool „Acoustic Ruler Pro“ hat – egal ob auf iPhone oder iPad eingesetzt – absolut nichts an seiner Nützlichkeit eingebüßt und wird nach wie vor jedem empfohlen, der mal Grund in sein Setup bringen möchte. Es gibt schlicht keinen einfacheren, zuverlässigeren und günstigeren Weg, um wirklich zu messen was im eigenen Headset vor sich geht.
Auf Kopfhörer ganz zu verzichten ist für versierte PodcasterInnen keine Option, denn:
- Immersion: man fühlt und spricht anders mit der eigenen Stimme im Kopf
- Skype und Mumble: wenn auch nur ein Gesprächspartner nicht im selben Raum sitzt, ist ein Kopfhörer unumgänglich
- Einspieler: Intro, Jingles, andere Soundquellen – all das will man live hören und nicht erst im Schnitt hinzuarbeiten.
Grundlagen: Was Latenz mit Körper-, Direkt- und Reflektionsschall zu tun hat
Kritisch ist nur die Latenz der eigenen Stimme. Hält man sich die Ohren fest zu oder versiegelt sie komplett und spricht, hört man sich immer noch selber. Der Schall der eigenen Stimme wird vom Knochengerüst des Körpers ins Ohr geleitet. Zwar dumpf und nicht allzu laut, aber dennoch gut genug. Dieses Phänomen ist als „Körperschall“ bekannt und der Grund dafür, dass wir unsere eigene Stimme auf Aufnahmen nicht ausstehen können – sie klingt immer eindimensional und ohne Bass. Dies sind genau die Anteile im Frequenzspektrum und die Laufzeitverschiebungen, die der Körperschall unserer eigenen Stimme hinzufügt. In diesem Fraunhofer-Beitrag ist das schön zusammengefasst: es gibt nur exakt einen Menschen, der unsere Stimme scheinbar „normal“ hört. Und das sind wir selbst.
Aus diesem Grund setze ich, gerade für Podcast-EinsteigerInnen – gerne EQ-Filter schon bei der Aufnahme im Monitoring ein: dreht man den Bass einfach etwas hoch um 110KHz, so hört sich die Stimme für die SprecherIn viel „normaler“ an, nicht so fremd.
Warum ist nun Latenz bei der eigenen Stimme so ein großes Problem? Der Körperschall kommt praktisch unmittelbar in unserem Ohr an – er muss sich nicht durch Luft arbeiten und reflektieren, sondern geht direkt durch Knochen und Zähne. Alles was wir sprechen, kommt also mit 0ms Verzögerung im eigenen Ohr an. Unser Gehirn ist es gewohnt, eine weitere Quelle mit einzurechnen: den reflektierten Schall unserer Stimme wie er von Wänden, Möbeln etc. an unser Ohr zurück kommt. Dieser Klang der eigenen Stimme überlagert sich zwar mit dem Körperschall und kommt – je nach Raum – einige Millisekunden verzögert an. Aber das ist das Gehirn ein Leben lang gewohnt. Bedingt durch die Schallgeschwindigkeit von 343 Metern pro Sekunde ergibt sich eine gerundete Latenz von ca. 3ms pro Meter. Sitzt man 3 Meter von einer reflektierenden Wand entfernt, ergibt das hin und zurück 6 Meter, also 6×3 = 18ms Latenz. Ziemlich viel. Im Audio-Bereich für Sprache eigentlich komplett inakzeptabel, warum ergibt das im Alltag dennoch kein Problem? Das liegt an der neben Körperschall und Reflektionsschall bisher unterschlagenen, dritten Klangquelle unserer Stimme: dem Direktschall von Mund zu Ohr. Der ist zwar minimal langsamer als der Körperschall, die wenigen Zentimeter Entfernung werden aber dennoch in weniger als 1ms zurückgelegt. Dieser Direktschall ist auch dafür verantwortlich, dass wir beim Sprechen im Freien etwas von unserer Stimme hören, außer dem Körperschall – denn Reflektionen fehlen ja etwa auf einer grünen Wiese (wir bleiben mal bei einem einfachen Modell ohne Wind).
Dieser Direktschall von Mund zu Ohr ist relativ laut. Ich habe leider keine wissenschaftlichen Quellen dazu gefunden, würde aber vermuten, dass sich die Komponenten unserer Stimme, in einem normalen Raum gesprochen, in etwa so zusammensetzen: 30% Körperschall, 50% Direktschall, 20% Echo/Reflektionsschall (wenn jemand eine Messung hat: gern her damit).
Was passiert nun in einer Podcast-Situation? Man hat ein Mikrofon direkt vor dem Mund, dazu mehr oder weniger gut abschirmende Kopfhörer auf. Der Körperschall bleibt immer gleich laut. Durch den Kopfhörer werden jedoch die anderen beiden Anteile stark gedämpft – je nach Kopfhörer unterschiedlich stark. Dafür wird jedoch der Monitor-Klang des Soundinterfaces eingespielt, quasi als Ersatz für Direktschall und Reflektionsschall. Wird nun der latenzfreie, sonst dominante Direktschall ersetzt durch latenzbehafteten Monitoring-Schall, gerät unser Gehirn ins Trudeln, die Laufzeiten sind nicht die erwarteten.
Die Toleranz für Latenz ist bei jedem Menschen unterschiedlich. Alles unter 4ms ist unkritisch. Der Bereich von 4ms bis 6ms wird mal mehr, mal weniger als etwas irritierend empfunden. Von 6ms bis 10ms hören alle Menschen den Effekt, manche können ihn noch so eben tolerieren. Ab 10ms ist das vorbei: die Latenz ist so groß, dass man beginnt langsamer zu sprechen um die Laufzeiten auszugleichen, ein entspanntes Sprechen ist nicht mehr möglich.
Zurück zu unserem Presonus-Problem. Ausgestattet mit Acoustic Ruler, einem Zoom H6 als Referenzinterface, meinem Presonus VSL 1818, Beyerdynamics Headsets, einem Early 2015 MacBook Pro, OSX 10.11 El Capitan, Ultraschall und 5 Stunden Zeit haben @gglnx und ich alles durchgemessen was uns sinnvoll erschien.
Erster Test: Das Zoom H6 als Referenz
Ein Monitoring im Hardware-Soundinterface kommt – ordentliche A/D-D/A Wandler vorausgesetzt – praktisch immer latenzfrei daher. Eine Überraschung erlebt man hier beim Zoom H6: die Grundlatenz des Monitorings liegt schon bei 3,9ms ohne jegliche aktivierte Effekte. Für die Praxis absolut brauchbar, aber doch erstaunlich hoch. Nimmt man Effekte wie Limiter oder Kompressor hinzu, steigt die Latenz auf grenzwertige 5,2ms. Da sich aber bisher noch niemand lautstark über diese Latenz beschwert hat, bestätigt sich obige Regel: alles unterhalb von 6ms ist in Ordnung.
Zweiter Test: Presonus ohne Effekte
Der wichtigste Test kam zuerst: welche Latenz wird erzielt, wenn man über die Routing-Matrix von Reaper/Ultraschall das eigene Mikrofonsignal unbearbeitet wieder an das VSL1818 zurückschickt? Wäre dieser Wer zu hoch (> 6ms) stünde ein Verkauf des Gerätes an – man würde schlicht die eigene Stimme nicht hören können.
Die gute Nachricht: die erzielte Latenz lag mit 4,4ms im grünen Bereich – nur knapp über dem H6 ohne Effekte. Dies ist insofern beachtlich, als dass in dem oben verlinkten Grundlagenartikel von Presonus als maximal erzielbare Latenz 5ms angegeben wurde. Wir sind also mit dem neuen Setup sogar schneller als wir es mit dem alten jemals waren.
Einen deutlichen Einfluss hat hierbei die in Reaper/Ultraschall einstellbare Block-Size für den Audio-Buffer. Generell gilt: je kleiner, desto niedriger kann man die Latenz drücken, unterhalb von 16 ergibt sich jedoch keine Verbesserung mehr. Unsere Messwerte:
- Buffer bei 512: nicht mehr messbar hoch
- Buffer bei 128: 9,1ms
- Buffer bei 64: 6,5ms
- Buffer bei 32: 5,1ms
- Buffer bei 16: 4,4ms
- Buffer bei 8: 4,4ms
- Buffer bei 4: 4,4ms
Generell gibt es hier einen Trade-Off zwischen Stabilität und Performance. Buffer unter 16 sind für Aussetzer und Knackser definitiv anfällig. Je älter der Rechner, desto höher muss man den Buffer setzen. Wir liefern Ultraschall mit einem sehr konservativen Wert von 512 aus. Bisher wurde ja die eigene Stimme nicht durch Reaper für das Monitoring geführt, und bei allen anderen Stimmen ist die Latenz schlicht egal dank fehlendem Körperschall.
Will man diesen neuen Monitoring-Weg beschreiten, sollte man daher sorgfältig probieren, wo die Performance des eigenen Rechners liegt und wann Störungen hinzukommen.
Dritter Test – Effekte
Generell ermutigt haben wir als nächstes getestet, welchen Einfluss Effekte in Reaper/Ultraschall auf die Latenz haben. Das VSL1818 hatte – wie oben erwähnt – Effekte, und auf diese möchte man eigentlich nicht verzichten.
Der erste Versuch war wenig ermutigend: der von uns geliebte „Dynamic Processor“ Effekt – Limiter, Kompressor und Expander kombinierend – ließ die Latenz auf nicht akzeptable 15ms hochschnellen.
Sehr viel besser sah es aber bei den mit Reaper mitgelieferten, von Cockos handgeschmiedeten Rea* Effekten aus. EQ, Limiter, Noisegate und Kompressor bringen keine nennenswerte zusätzliche Latenz in die Kette. Selbst wenn alle gleichzeitig aktiviert sind, werden 5,1 ms nicht überschritten. Das ist knapp besser als das H6. Und im Ergebnis schlicht der Durchbruch: alle im VSL bisher angebotenen Effekte können im neuen Setup ebenfalls genutzt werden, ohne dass die Latenz steigt. Dazu kann man sie wesentlich flexibler parametrisieren als das in der doch eher kargen VSL-Mixersoftware je der Fall war.
Selbst wenn es die Mixersoftware für El Capitan gäbe, würden wir diese neue, rein Reaper-interne Behandlung empfehlen – je weniger Komponenten in der Kette, desto besser.
Möglicherweise ist dieses Verfahren auch für andere Soundinterfaces geeignet: hier wären wir sehr an Vergleichsmessungen interessiert. Auch ist noch unklar, welchen Einfluss die CoreAudio Überarbeitungen von El Capitan auf die Latenz haben, und welche Werte unter Yosemite erzielt würden.
Vierter Test – Aggregate Device und Skype N-1
Eine Teststrecke war noch wichtig: wie verhält sich das Setup, wenn zusätzliche Komplexität in Form eines Aggregate Device und Skype N-1 Schaltung hinzukommt? Erste, wenig überraschende Erkenntnis: die Tage von Soundflower unter El Capitan sind beendet. Unser letzter, angepasster USH-Treiber – im Kern immer noch auf Soundflower basierend – läuft zwar, allerdings immer mit extremem Knacksen und Störungen. Auch bei hoch eingestelltem Buffer von 128.
Abhilfe bringt hier der von Daniel gerade neu entwickelte Ultraschall Hub Treiber: El Capitan only, und direkt entlang der neuen Core-Audio-API entwickelt. Skype wurde nutzbar, wenn auch zu einem Preis. Bei einem Buffer von 16 stieg die Latenz von 4,4ms auf 5,2ms und es kam relativ regelmäßig zu Knacksern. Bei 32 verschwanden diese fast vollständig, die Latenz lag ebenfalls um 0,7ms höher: 5,8 statt 5,1. Keinerlei Störungen gab es mehr bei einem Buffer von 64: die 7,2ms Latenz haben uns dann jedoch schon ziemlich gestört.
Generell ist hier noch Grundlagenforschung notwendig, auch die Arbeiten am Hub sind noch nicht abgeschlossen. Wir sind aber zuversichtlich, hier mit unserer Ultraschall 2.0 Release zum #ppw15b Klarheit zu haben.
Fazit
Im Ergebnis ist der eingestellte Presonus-Support für die VSL-Geräte wohl nicht die gefürchtete Katastrophe. Der Device „Scheitern als Chance“ folgend haben wir – zumindest auf aktuellen Macs – gute Chancen, mit größerer Kontrolle ein besseres Setup zu fahren als bisher – solange man keine Aggregate Devices benötigt. Für diese Ferngesprächs-Setups ist noch weitere Forschung notwendig – Messwerte gerne im Sendegate einbringen!